

Linear regression is a simple yet powerful tool used in machine learning and statistics to predict a continuous outcome variable (dependent variable) based on one or more predictor variables (independent variables). In this notebook, we will implement linear regression from scratch, without using any libraries, to understand its mechanics deeply.
Visit notebook
Binary logistic regression is a type of regression analysis used to predict the probability of a binary outcome based on one or more predictor variables. It's widely used in various fields, including medicine, economics, and social sciences, where predicting categorical outcomes is essential.
Visit notebook
In this notebook, we will explore the Titanic dataset, preprocess the data, and build a Random Forest model to predict the survival of passengers. The steps involved are:

A decision tree is like a flowchart that helps make decisions. It starts with a single question at the top (root) and branches out based on the answers, leading to more questions or final decisions (leaves).
Visit kaggle Notebook
Random Forest is an ensemble learning method that combines multiple decision trees to make more accurate predictions. Each tree in the forest is trained on a random subset of the data and features.
Visit kaggle Notebook
Support Vector Machines (SVM) are powerful supervised learning models used for classification and regression tasks. In this notebook, we will dive into the fundamentals of SVM and implement a simple version from scratch using Python. We'll also visualize the concepts to gain a better understanding.
Visit kaggle Notebook
K-Nearest Neighbors (KNN) is a simple, instance-based learning algorithm used for both classification and regression tasks. It is easy to understand and implement, making it a popular choice for beginners. The basic idea is that a data point is classified by the majority class among its K nearest neighbors.
Visit kaggle Notebook
Naive Bayes is a probabilistic machine learning algorithm used for classification tasks. It's known for its simplicity and effectiveness in various real-world applications.
Visit kaggle Notebook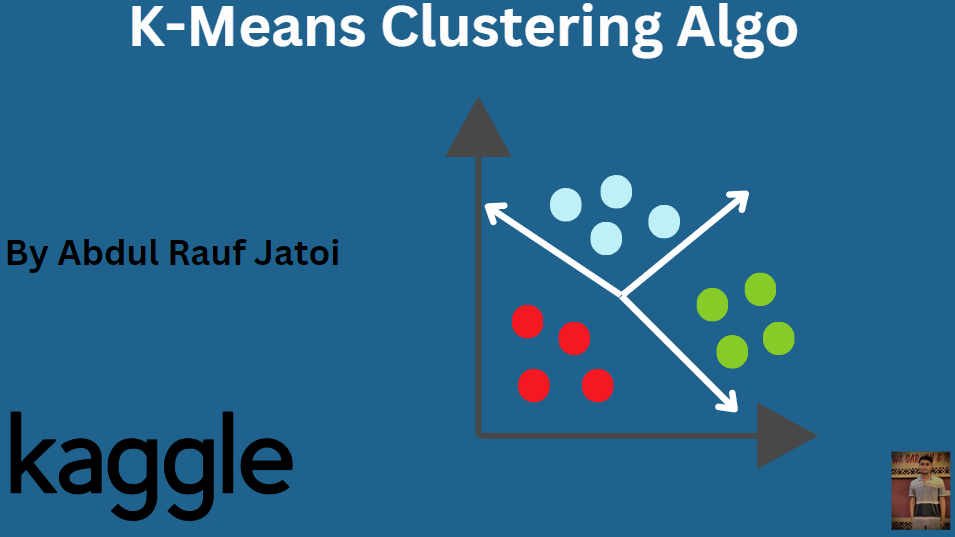
K-means clustering is a method to group data points into K clusters based on similarity. It's widely used in data analysis for segmentation and pattern recognition.
Visit kaggle Notebook
Gradient Boosting Machines (GBM) are ensemble learning methods that combine multiple weak learners, typically decision trees, to create a strong predictive model

AdaBoost, short for Adaptive Boosting, is a powerful ensemble learning technique that combines multiple weak classifiers to create a strong classifier. It is particularly effective in improving the accuracy of models by focusing on misclassified instances. This notebook will guide you through the fundamentals of AdaBoost, its implementation from scratch, and visualization, making the concept easy to understand and apply.

Neural networks have revolutionized the field of artificial intelligence and machine learning. They are the backbone of many modern technologies, enabling advancements in computer vision, natural language processing, and more. This notebook aims to provide a comprehensive understanding of neural networks, from basic concepts to hands-on implementations.
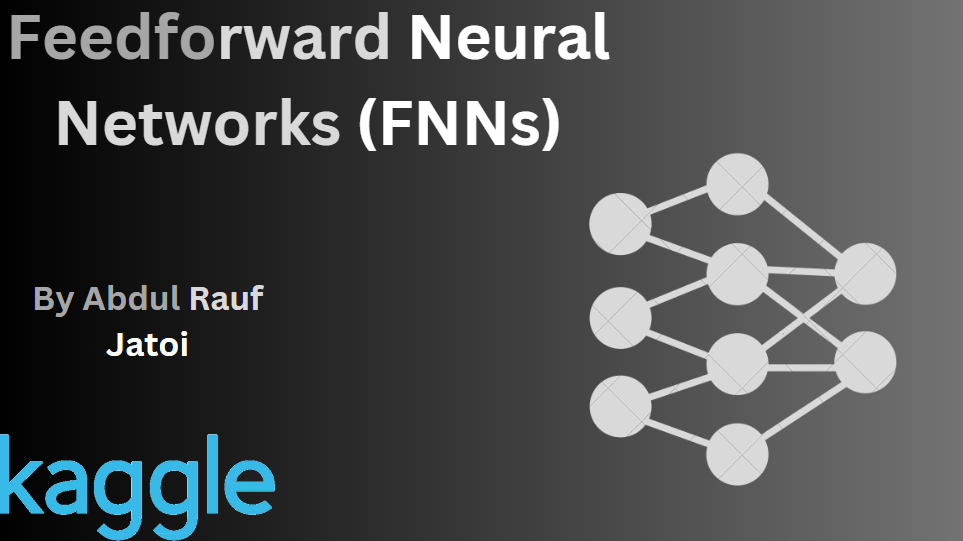
This notebook provides a comprehensive guide to understanding and implementing Feedforward Neural Networks. By following the steps and code provided, you can build your own FNN models and apply them to various tasks.

Sentiment Analysis Using FNN and CNN to compare and get the best one
Digits recognition using Recurrent Neural Network get almost 97% accuracy and about 0.11 loss ( thas pretty good )

In this notebook, we'll explore various types of neural networks, from foundational concepts to advanced architectures, using TensorFlow/Keras for implementation.
Visit Colab Notebook
In this notebook, we explore the fundamentals of Feedforward Neural Networks (FNNs), a cornerstone in deep learning.
Visit Colab Notebook
Neural networks are powerful machine learning models inspired by the human brain. They consist of interconnected layers of neurons that process and learn from data to make predictions. In this tutorial, we'll build a neural network step-by-step to classify handwritten digits from the MNIST dataset.
Visit Colab Notebook
This Notebook has provided an overview of CNNs, their implementation in Google Colab using TensorFlow and Keras, and visualizations to better understand their inner workings and advantages in image analysis tasks.
Visit Colab Notebook
Recurrent Neural Networks (RNNs) are a type of artificial neural network designed to recognize patterns in sequences of data such as text, genomes, handwriting, spoken words, and numerical time series data. They are widely used in tasks where the order and context of data points are important.
Visit Colab Notebook
Long Short-Term Memory (LSTM) networks are a type of recurrent neural network (RNN) designed to overcome the limitations of traditional RNNs in capturing long-term dependencies in sequential data. They are widely used in applications requiring memory over time, such as natural language processing (NLP), time series prediction, and speech recognition.
Visit Colab Notebook
Generative Adversarial Networks (GANs) are a class of machine learning frameworks designed by Ian Goodfellow and his colleagues in 2014. GANs consist of two neural networks, a generator and a discriminator, that compete against each other. This competition leads to the generation of realistic data.
Visit Colab Notebook
Transformers are a type of deep learning model that has revolutionized natural language processing (NLP). They are based on the self-attention mechanism and have been widely adopted due to their effectiveness in capturing long-range dependencies in sequences.
Visit Colab Notebook







.png)
